일본의 민자 전력발전사 이렉스 (eREX, 동경증시 1부 상장, T9517)의 최근 주가 심상치 않다...
6.21 기준 주당 2,027엔이었는데, 2주만에 2,774엔으로 급등했다.
2주간 무려 36%나 올랐다.
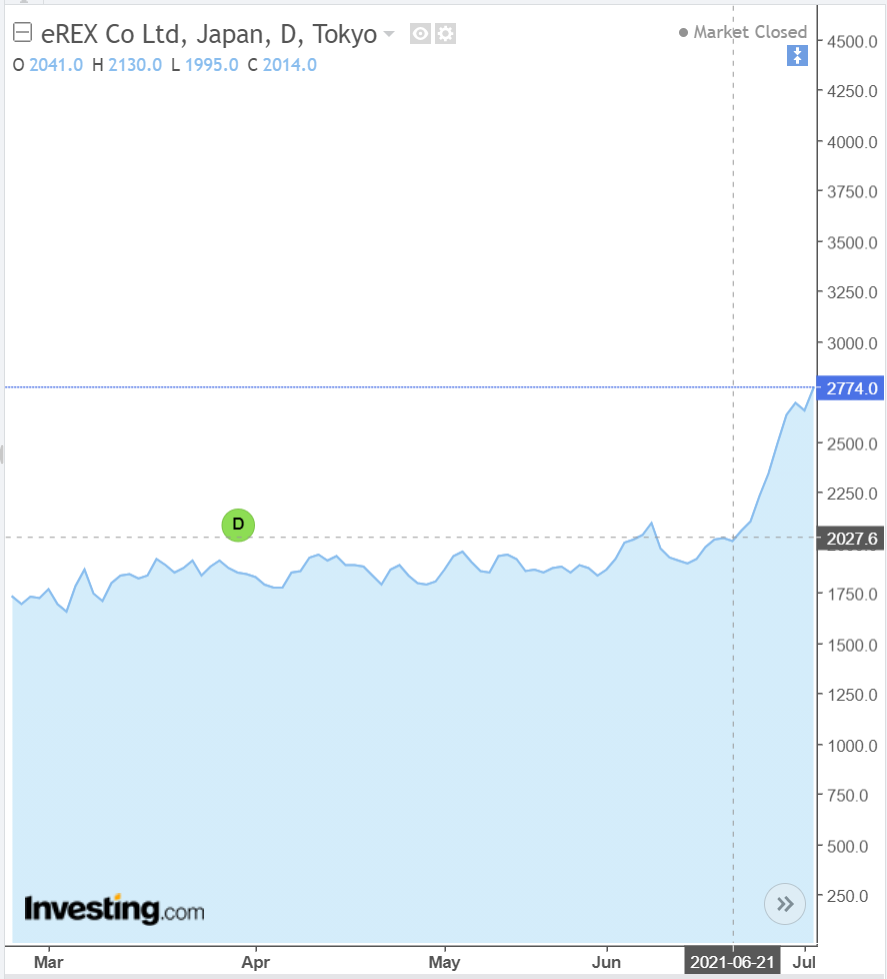
도대체 왜 이렇게 올랐을까, 일본 사람들은 어떤 생각으로 이 종목에 투자하는지 궁금해졌다.
우리나라 상장사의 경우 네이버 종목토론방을 통해서 간략하게나마 투자자들의 심리를 엿볼 수 있는데, 일본에도 그런 커뮤니티가 있을까 궁금했다.
찾아보니 있었다.
약 1개의 글 단위로 하나의 쓰레드 (Thread)가 있고, 이번에 급등한 주의 6.5 ~ 7.1 기간동안의 글들이 모인 쓰레드가 있다.

사람들이 글을 올리면, 다른 사람들은 공감/비공감을 클릭할 수 있다.
약 1,000개의 글이 올라와 있는데, 어떤 내용인지 한번 살펴보고 싶어서 코드를 작성했다.
분석 전략
- 각 글을 하나의 행으로 하는 dataframe을 만든다.
- 구글의 cloud translation api를 통해서 각 글의 한글 번역본을 column으로 추가한다.
- 그래도 공감을 많이 받은 글은 이유가 있겠거니 해서 공감순으로 dataframe을 정리해본다.
분석 결과
1. 역시 오를 때 글이 많이 달린다. 이번주에 글들이 폭주했다..

2. 공감을 많이 받았는데 개인적으로 인상적인 댓글들은 아래와 같다.
- 알기 쉬운 저점이었습니다 🙏 わかりやすい底打ちでございました🙏,
2021-06-15 11:23:00, 공감31 비공감 14)- 나중에 차트를 보면 알기 쉬웠을 수 있겠지만.. 저 적지 않은 비공감은 글쓴이의 오만함에 대한 반감인 것 같다.
- 박스를 벗어나 상승세를 탔다 일까. 더위 것 같은 올 여름도 순풍.
ボックスを脱して上昇トレンドに乗ったかな。暑そうな今年の夏も追い風。
2021-06-23 10:32:00, 공감 34 비공감 2- 역시 전력회사라 그런지 여름이 더운게 긍정적인 시그널이다.
- 기사에 따르면, 4 개 정도를 총 수백억 엔에 매입 전용 설비를 도입 한 지 22 년 이상 운전 개시를 목표로한다. 돌 화력 폐지가 세계적인 흐름과지면서 석탄 화력을 가진 선도적인 전력이나 철강, 자재 메이커에 있어서는 매각하기로 폐지 비용을 줄일 수 있다는 장점이있는 반면, 전자 렉스에게 ★ 감가 상각이 끝난 발전소를 매입함으로써 비용을 절감 할 수 있다는 장점이있는만큼, 기사에 관심이 강한 것 같다. 출력 15-50 만 kW의 발전소를 관동와 호쿠리쿠, 시코쿠 등으로 인수함으로써 주요 전력 및자가 발전소를 보유한 기업과 막바지 협상에 들어간 것으로 알려졌다. 바이오 매스 연료를 저장하는 저장 시설 및 분쇄기 등을 설치하여 당분간은 석탄 30 % 정도 섞어 발전. 25 년경에 100 %까지 증가하고있다.
記事によると、4基程度を合計数百億円で買い取り、専用設備を導入して22年以降の運転開始を目指すという。石 炭火力廃止が世界的な流れとなるなか、石炭火力を持つ大手電力や鉄鋼、資材メーカーにとっては売却することで廃止コストを省けるというメリットがある一方、イーレックスにとっては★減価償却が終わった発電所を買い取ることでコストを抑えることができるというメリットがあるだけに、記事への関心が強いようだ。出力15-50万キロワットの発電所を関東や北陸、四国などで買収することで、大手電力や自家 発電所を持つ企業と詰めの交渉に入ったという。バイオマス燃料を保管する貯蔵設備や粉砕機などを設置し、当面は石炭に30%程度混ぜて発電。25年ごろに100%まで高めるとしている。
2021-06-23 15:41:00, 공감 21 비공감 2- 주가상승의 트리거가 된 기사내용을 잘 짚어준 것 같다. 이렉스는 원래 바이오매스 화력 발전을 주 사업으로 하는 회사인데, 석탄 화력발전소를 인수해서 바이오매스 화력발전소로 전환하겠다는 기사가 6월 중순쯤에 나왔다.
- 해당 기사는 하기 링크 참고. 기사가 6.18(일) 오후에 올라왔고, 주가 상승세가 그때부터 시작되었으니 트리거로 보는 게 맞을 것 같다.
https://www.nikkei.com/article/DGXZQOUC09EBR0Z00C21A6000000/
- 투기주는 무서워. 투기주란 얼마 안되는 시간에 주가가 2배, 3배 아니 그 이상이 되는 주식으로 알고 있습니다.판매자와 구매자의 힘 겨루기입니다.투기전의 주식은 논리가 통하지 않아요.주가는 투기전이 끝났을 때의 주가입니다.지난 금요일 즈음부터 주가는 고개를 들고 있습니다.어디까지 주가가 오를지 설렙니다.옛날 얘긴데 지금은 불쌍한 창생그룹이지만 실수로 6000에서 25000까지 된적이 있어요.전문 분야가 다른 주식입니다만, 자금 조달전이란 이런 것이라고 생각하고 있습니다.내일도 기대가 됩니다판매자 각오는 되셨나요?
仕手株はおっかないよ。仕手株とは僅かな時間に株価が2倍、\r\n3倍いやそれ以上になる株と承知しています。売り手と買い手の力勝負です。仕手戦の株は理屈は通じません。株価は仕手戦が終了した時の株価です。先週の金曜日あたりから株価はかま首を持ち上げています。どこまで株価が伸びるのかワクワクしています。昔の話しですが\r\n今は哀れのそうせいグループですが過って6000から25000までになったことがあります。畑違いの株ですが仕手戦とはこんなものだと思っています。明日も楽しみです。売り手の方覚悟はいいですか。
2021-06-29 15:45:00 공감 19 비공감 9
- 급등에서 작전주, 투기주의 가능성을 경고하는 댓글이다. 기업이 자금 조달 직전이라 주가를 의도적으로 올리고 있다는 주장을 하고 있다. (자금 조달은 위에서 언급한 석탄화력 발전소 인수자금 마련을 위한 것으로 볼 수 있다.)
- 어제 젊은 사람의 봉급 사정을 들었어요.일단 이름이 알려진 회사공업 고졸이지만 실수령자는 16만. 이렇게 되면 저출산 고령화가 진행되겠네.생전 짧은 할아버지 임원보다는 이왕이면 젊은이가 줬으면 좋겠네.
昨日若い人の給料事情をききました。一応名の知れた会社。\r\n工業高卒なんだけれど、手取りで16万。これじゃ少子高齢化がすすむよね。\r\n老い先短いじじい役員よりも、どうせなら若者にあげてほしいよね。
2021-07-01 11:25:00, 공감10 비공감 1
- 급여 시스템에 대한 지적을 한 의외의 댓글이다. 그런데 공감도 의외로 많다. 월급이 실수령 기준 16만엔이면 원화로 160만원 정도인데 적긴 적은 것 같다.

코멘트
- 예상했던 것보다 훨씬 오랜 작업이 걸린 프로젝트였다. 단순한 호기심에서 간단하게 내용들을 보려고 했는데 아래와 같은 이유로 프로젝트 완성이 계속 지연됐다.
- 가져오고자 하는 데이터가 html table이 아니라서 pandas의 read_html를 바로 사용할 수 없다.. 어쩔 수 없이 beautifulsoup4로 처음부터 코드를 짜야 했다.
- papago api를 사용하다가 계속 429 connection error가 나와서 결국 google cloud translation api를 사용했다. 이걸로 전환하는 과정에서 또 예상치 못한 시간이 지연됐다.
- 솔직히 말하자면, 생각보다 유의미한 내용은 없는 것 같다.. 역시 인터넷 글들을 신중하게 거르는게 좋을 수 있다..
코드
import json
import requests
import pandas as pd
from bs4 import BeautifulSoup as bs
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]="your json file"
import urllib.request
import re
def deEmojify(text):
regrex_pattern = re.compile(pattern = "["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
"]+", flags = re.UNICODE)
return regrex_pattern.sub(r'',text)
def process_list(list):
# 먼저 \r ,\n 처리 # 이것도 굳이 구글이면 안해도 될듯
# t1 = [i.replace("\r\n","") for i in list]
# t1 = [i.replace("\r","") for i in t1]
# t1 = [i.replace("\n","") for i in t1]
# 이모지 지우기 # 이거 구글이면 굳이 안해도 될듯
# t1 = [deEmojify(i) for i in t1]
# 안지워지는 \u3000 지우기
t1 = [i.replace("\u3000","") for i in list]
# url 지우기
t1 = [re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+', '', i) for i in t1]
return t1
# helper functions
def codelist(offset,page,code):
offset = 1131
page = 0
code = 1625223125919
offsetlist = [[offset,page,code]]
while offset > 0:
offset = offset - 21
page = page + 1
code = code + 1
offsetlist.append([offset,page,code])
# drop negative values
offsetlist = [item for item in offsetlist if item[0] >= 0]
return offsetlist
def to_df(html):
soup = bs(html, 'html.parser')
text1 = soup.findAll('p', attrs = {'class': 'comText'},limit=None)
textlist = [x.text for x in text1]
like_1 = soup.findAll('li', attrs = {'class': 'positive'},limit=None)
likelist = [[x.text for x in y.findAll('span')][0] for y in like_1]
dislike_1 = soup.findAll('li', attrs = {'class': 'negative'},limit=None)
dislikelist = [[x.text for x in y.findAll('span')][0] for y in dislike_1]
date1 = soup.findAll('p', attrs = {'class': 'comWriter'},limit=None)
datelist = [[x.text for x in y.findAll('a')][1] for y in date1]
df = pd.DataFrame(
{'date': datelist,
'content': textlist,
'likes': likelist,
'dislikes':dislikelist})
# add month
df['date'] = '2021年'+df['date']
# change to datetime
df['date'] = pd.to_datetime(df['date'], format='%Y年%m月%d日 %H:%M')
return df
def translate_text(target, text):
"""Translates text into the target language.
Target must be an ISO 639-1 language code.
See https://g.co/cloud/translate/v2/translate-reference#supported_languages
"""
import six
from google.cloud import translate_v2 as translate
translate_client = translate.Client()
if isinstance(text, six.binary_type):
text = text.decode("utf-8")
# Text can also be a sequence of strings, in which case this method
# will return a sequence of results for each text.
result = translate_client.translate(text, target_language=target)
return result["translatedText"]
# returns a df with translation added
def add_trans(df,target_lang):
# target_lang = 'ja', 'ko'
# get content as list
mytarget = target_lang
contentlist = df['content'].tolist()
# 전처리
contentlist = process_list(contentlist)
# translate
resultlist = [translate_text(mytarget,i) for i in contentlist]
# add to df
df['translated'] = resultlist
return df
def get_erex():
# get a list of offset, page and code when we have first values
offset1 = 1131
page1 = 0
code1 = 1625223125919
mycodes = codelist(offset1,page1,code1)
# start session
cookieurl = 'http://yahoo.co.jp'
client = requests.session()
response = client.get(cookieurl)
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36',
'Content-type':'application/x-www-form-urlencoded; charset=UTF-8',
'Accept':'application/json, text/javascript, */*; q=0.01',
'referer':'https://finance.yahoo.co.jp/cm/message/1834873/fb170d917fd47bbe484a2e7d89a48428/56',
'accept-encoding': 'gzip, deflate, br',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'x-requested-with':'XMLHttpRequest'
}
# loop through each pages
dfs = []
for i in mycodes:
url = f'https://finance.yahoo.co.jp/cm/ds/comment/listview?category=1834873&thread=fb170d917fd47bbe484a2e7d89a48428&part=56&spaceid=2080515752&thread_feel_type=1&thread_stop_flag=1&reputation_detail=%E3%81%9D%E3%81%86%E6%80%9D%E3%81%86%2C%E3%81%9D%E3%81%86%E6%80%9D%E3%82%8F%E3%81%AA%E3%81%84&tieup_name=finance&thread_name=9517%20-%20%E3%82%A4%E3%83%BC%E3%83%AC%E3%83%83%E3%82%AF%E3%82%B9(%E6%A0%AA)&offset={i[0]}&page={i[1]}&_={i[2]}'
response = client.get(url=url,headers=headers).json()
myhtml = response["feed"]["content"]
df = to_df(myhtml)
dfs.append(df)
# add all dfs
df = pd.concat(dfs, ignore_index=True)
# change all numbers to int
df['dislikes'] = df['dislikes'].astype(int)
df['likes'] = df['likes'].astype(int)
df = df.drop_duplicates('content')
return df'Projects > Renewable Energy' 카테고리의 다른 글
| 구글 스프레드시트로 RE100 대시보드 만들기 (4. Overview 대시보드 만들기) (0) | 2022.03.01 |
|---|---|
| 구글 스프레드시트로 RE100 대시보드 만들기 (3. 트리거 설정 및 업데이트 자동화) (0) | 2022.02.28 |
| 구글 스프레드시트로 RE100 대시보드 만들기 (2. 데이터 수집) (0) | 2022.02.15 |
| 구글 스프레드시트로 RE100 대시보드 만들기 (1. 대시보드 소개) (1) | 2022.02.14 |
| [파이썬] RE100 선언한 기업 리스트 가져오기 (0) | 2021.06.29 |



