이번 편에서는 실제로 대시보드를 어떻게 만들었는지, 각 요소별로 어떤 방식으로 데이터를 가공하여 시각화하였는지를 살펴볼 예정이다.
4편에서는 대시보드의 첫번째 부분인 'Overview'애 대해서 살펴볼 예정이고,
5편에서는 대시보드의 두번째 부분인 'Deep Dive' 에 대해서 살펴볼 예정이다.

2~3편을 통해서 웹페이지에서 데이터를 수집하고, 시트에 자동으로 업데이트하는 시스템을 구축하였고, 그 결과 아래와 같은 dataset이 준비되어 있다.

이 dataset을 이용해서 대시보드의 각 요소를 하나씩 구축할 예정인데,
대시보드의 각 요소에 대한 자세한 설명은 1편에 적어두었다.
① 최근에 업데이트된 항목 가져오기 : Recent Updates
'최근'의 기준 설정
'최근'이라는 것은 항상 기준 시점에 따라서 달라지기 때문에, 언제를 '최근'으로 볼 것인가에 대해서 사전 정의가 필요하다.
즉 어떤 날짜를 '최근 날짜'로 볼 지에 대한 기준점 설정이 필요한데, 아래와 같이 Today() 함수를 통해서 이 기준을 설정할 수 있다.
이번 대시보드에서는 '오늘 기준으로 90일 전'을 기준일로 정의하고, 기준일보다 뒤에 오는 날짜는 모두 '최근'이라고 볼 예정이다.

이렇게 함수로 만든 셀을 선택한 다음, Ctrl+J를 입력하고 'recent_date'이라고 정의해주면 이 날짜를 앞으로 다른 함수에서도 'recent_date'이라는 변수로 사용할 수 있다.

'query function'의 활용
여기서는 queryfunction을 이용해서, 최근에 업데이트된 항목만 담은 테이블을 별도의 시트에서 생성하였다.
엑셀과 차별되는 구글시트의 가장 강력한 기능 중 하나가 queryfunction인데, queryfunction을 통해서 내가 원하는 거의 모든 방식으로 원본데이터에서 필요한 부분만 가져올 수 있다.

Queryfunction의 구문은 크게 3개의 부분으로 나눠어져 있다.
= query (①원본데이터 범위, ②query 구문, ③ (선택) 헤더 행 번호)
이 방식으로 위 식을 그대로 해석하면,
① data시트의 B1:G 범위를 원본 데이터로 해서,
② "select G,B,D where G >= date '"&TEXT(recent_date,"yyyy-mm-dd")&"'" 라는 query 구문을 실행하고
- select G,B,D : 원본데이터에서 순서대로 G열 (updated date), B열 (company), D열(target year)을 선택하기
- where G >= date '"&TEXT(recent_date,"yyyy-mm-dd")&"'" : G열의 날짜가 recent_threshold이라는 변수에 저장되어 있는 날짜보다 뒤인 값만 필터링하기 (추후 설명)
③ 원본 데이터의 1번 행을 헤더 행으로 설정하기
- 만약 이 값이 0으로 지정하는 경우 : 0번 행을 헤더 행으로 설정하기 ( = 헤더 행을 설정하지 않기)
- 만약 이 값을 3으로 지정하는 경우 : 1~3번행을 헤더 행으로 설정하기
로 볼 수 있다.
이렇게 최근 90일 이내에 업데이트된 항목만 따로 뽑아내는 테이블을 생성하였다.
대시보드 시트에서는 이 테이블을 그대로 불러와주면 되는데, 기타 차트 중 '테이블' 차트를 이용해주면 된다.
데이터 범위로는 위에서 생성한 테이블의 범위를 입력해주면 되는데, 여기서 행 범위는 시트의 마지막 행까지로 해둔다.
(D1000)
이렇게 해두는 경우 데이터가 추가되더라도 테이블의 행이 늘어나더라도 대시보드에 문제 없이 자동으로 반영된다.

② 스코어보드 (Scoreboard)
스코어보드 제작에서 필요한 수치는 4가지이다.
1. 22년까지 누적 가입 기업 수
2. 작년('21년)까지의 누적 가입 기업 수
3. 22년까지 누적 가입 한국기업 수
4. 작년('21년)까지의 누적 가입 한국기업 수
보조시트에서 각 수치를 함수로 아래와 같이 정의해준다.

그 다음 차트 → 스코어카드에서 데이터 범위를 아래와 같이 설정해준다.

맞춤설정으로 들어가서는 키 값 (351) 폰트 크기 설정, 기준값 설명 추가, 차트 제목 추가 등의 작업을 진행할 수 있다.

③ 신규 참여 기업 추이 (Number of New Members)
신규 참여 기업 추이 차트를 만들기 위해서는 원본 데이터에서 참여 연도(join_year)를 행으로 하는 피벗테이블을 만들어야 한다.
피벗테이블은 내가 원하는 기준별로 데이터를 구분하고 싶을 때 활용한다.
여기서는 각 연도별로 데이터를 구분해서, 각 연도별 개수를 구한다.
원본데이터를 전체 선택한 후 (Ctrl+A), 삽입 → 피벗테이블을 선택해서 새로운 시트에서 피벗테이블을 생성한다.
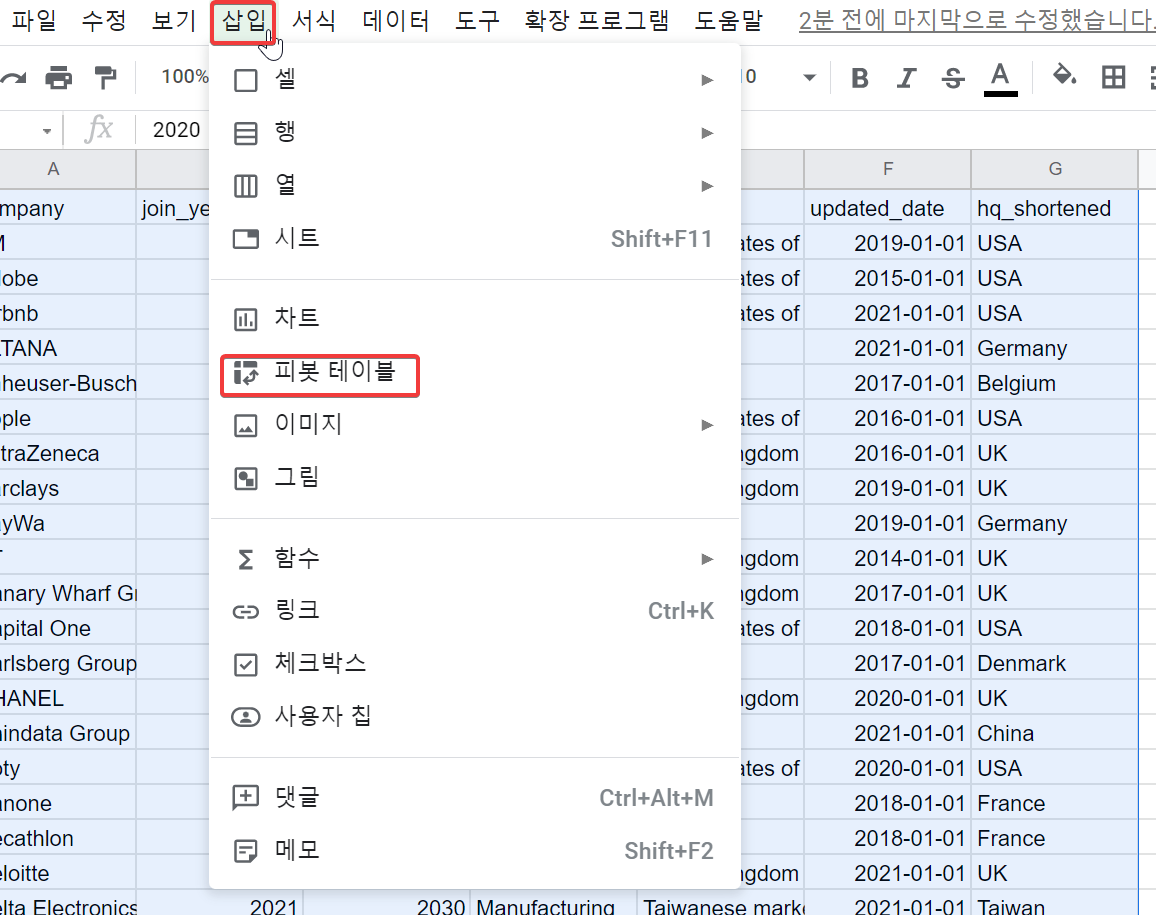
다음과 같이 빈 피벗테이블이 생성되는데, 가장 우측에서는 원본데이터의 각 열이 표시된다.
여기서 join_year 열은 '행'으로 드래그해주고, company 열은 '값'으로 드래그해 준다.
그리고 합계 표시는 체크 해제를 해준다.

이렇게 만들어진 테이블을 이용하면 다음과 연도별 가입자 추이 막대 그래프를 만들수 있다.
④ Where are the HQ's Located (RE100 선언 기업의 국가 분포)
마지막으로 각 기업의 본사가 어떻게 분포되고 있는지를 세계 지도를 통해서 표현해볼 수 있다.
이 차트를 만들기 전에도 ③에서와 같이 보조 피벗테이블을 활용한다.
(전 단계에서 만들어둔 피벗테이블을 그대로 복사해서, 우측에 붙여넣기를 해서 바로 만들 수 있다)
이번에는 행에서 참여연도(join_year)를 제거하고, 대신 본사 위치 (hq)를 추가한다.
마찬가지로 합계 표시는 체크 해제를 한다. (합계 표시 체크 해제를 하는 이유는 차트에서의 왜곡을 방지하기 위해서다.)

이렇게 생성된 피벗테이블을 선택한 후 차트를 생성하고, 차트 종류를 '마커가 있는 지역 차트'로 변경한다.
구글 시트에서는 hq 열의 국가 명을 자동으로 인식하고, 각 국가의 위치에 알맞게 지도에 마커를 표시한다.
본사가 많은 미국이나 일본과 같은 지역에서는 마커가 크게 표시되고 있는 것을 볼 수 있다.

'Projects > Renewable Energy' 카테고리의 다른 글
| 구글 스프레드시트로 RE100 대시보드 만들기 (5. Deep Dive 인터렉티브 대시보드 만들기) (1) | 2022.03.12 |
|---|---|
| 구글 스프레드시트로 RE100 대시보드 만들기 (3. 트리거 설정 및 업데이트 자동화) (0) | 2022.02.28 |
| 구글 스프레드시트로 RE100 대시보드 만들기 (2. 데이터 수집) (0) | 2022.02.15 |
| 구글 스프레드시트로 RE100 대시보드 만들기 (1. 대시보드 소개) (1) | 2022.02.14 |
| [파이썬] 일본 종목토론방 살펴보기 (ft. 전력회사 이렉스) (0) | 2021.07.03 |



